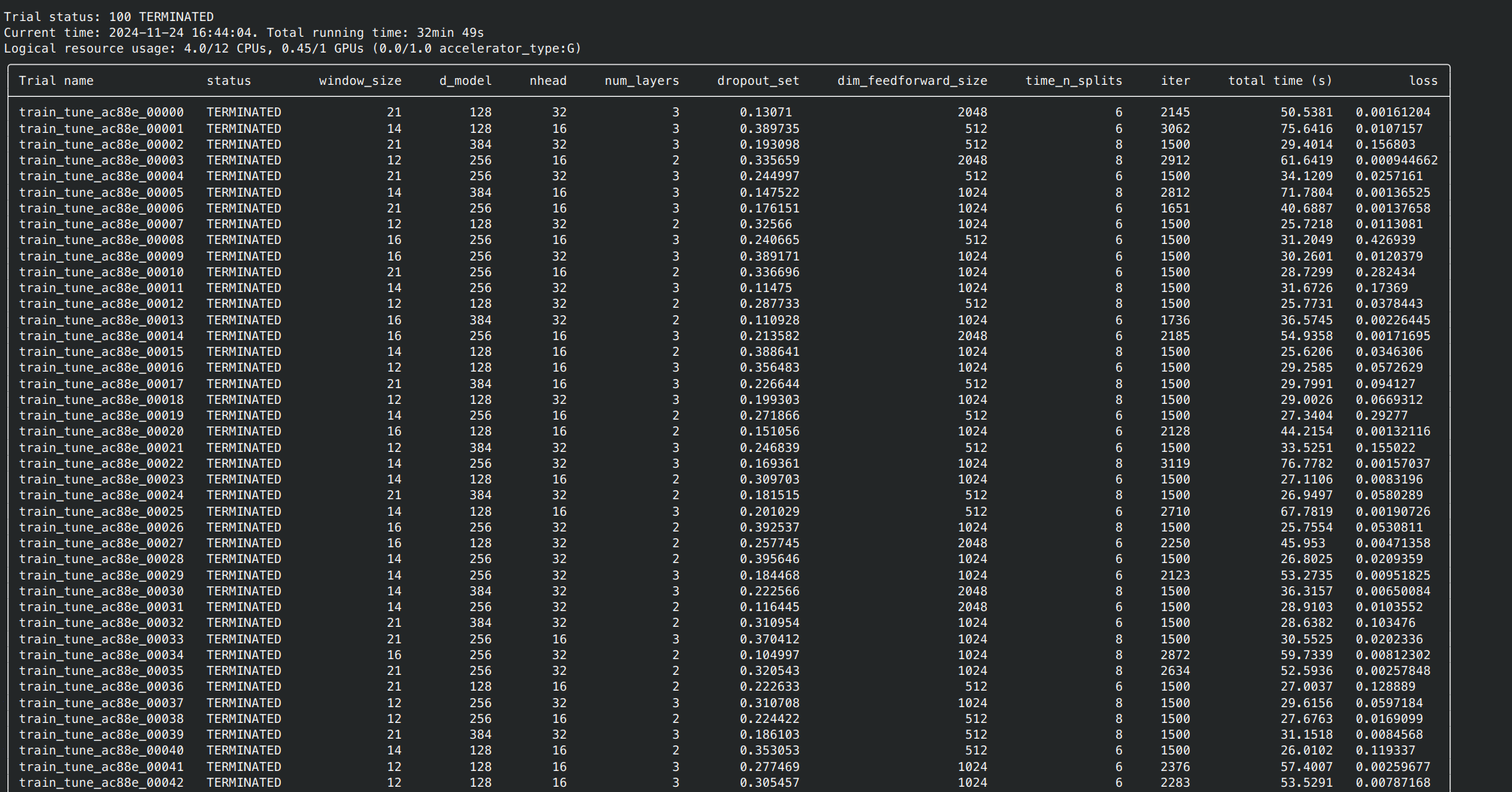
使用ray.tune进行自动调整超参数
对于模型而言,其超参数设置好坏可以显著影响其性能。然而显然手动调整实在有些折磨,我们可以使用一些工具来进行自动调整模型超参数,例如本文使用的ray.tune进行调整。其仅需要在原本的代码上改动十几行即可开始自动调整(个人认为比NNI更简单易用一些)。
前言
实际上如果你在网上搜索,大部分教程使用的都是NNI(Neural Network Intelligence)。但是NNI已经停止开发许久,并且其储存库也在今年9月被设置为存档只读了。
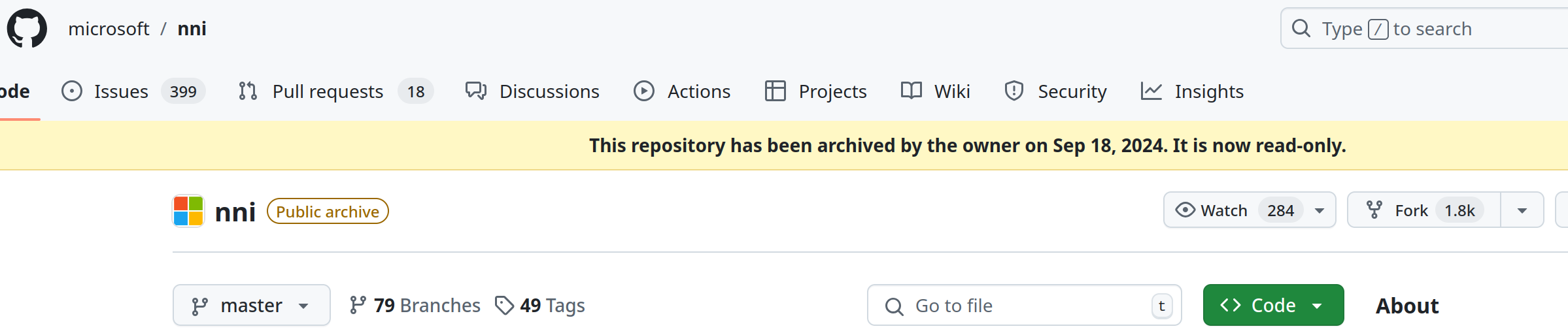
更不幸的是,我在使用NNI时遇到了严重的BUG,导致我无法使用NNI去进行调参(否则也不会有本文了)。如下图所示,设置的运行100次查找最优超参数,但是无论如何设置,在运行完2轮后其会停滞,不再继续运行。
使用ray.tune
重要
以下内容是基于:
torch = 2.5.1
ray = 2.39.0
编写的,不过只要你别用太过于古老的版本就没什么问题
安装
ray实际上是一个统一框架,用于分布式部署/训练应用。不过此处我们仅需要使用其进行超参数调整,仅需安装其与tune相关部分:
pip install "ray[tune]"修改原有程序
要在现有程序上修改,仅需要对四个地方进行修改:
- 定义搜索空间
- 修改训练函数,使其向ray报告当前训练参数
- 调用新的训练函数
- 查看调参结果
定义搜索空间
import ray
from ray import tune
from ray import train as session
#导入所有需要的部分
#...其他代码
config = {
"aaa": tune.choice([128, 256, 512]),
"bbb": tune.choice([512, 1024, 2048]),
"ccc": tune.choice([2, 4, 6, 8]),
"dropout_set": tune.uniform(0.1, 0.4),
}搜索空间即ray会在指定的范围内调整给定的超参数。例如上方的aaa,bbb,ccc超参数是一个选择类型的,其从给出的表中选择一个,而dropout_set则是一个范围,其会从0.1-0.4中选择一个数进行调整。更多的搜索空间定义你可以参照ray的官方手册,你甚至可以自己定义一个lambda函数来生成搜索范围。
修改训练函数
显然在函数训练过程中,ray需要知道一个衡量当前超参数对应模型的好坏指标。其可以是一个准确度或损失。在此处我使用的是loss(越低越好),因此在随后的设置中衡量mode设置的为min。如你使用的是准确度,你需要相应地将其调整为max。
#...其他代码
def train_tune(config, xxx, device) #其中xxx是假设的其他需要的入参
#...网络定义
model = Model(
aaa = config["aaa"],
bbb = config["bbb"],
ccc = config["ccc"],
dropout_set = config["dropout_set"],
).to(device)
#...其他代码
for epoch in range(num_epochs):
#...其他代码
# 报告每个epoch的验证损失
session.report({"loss": val_loss.item()})
#...其他代码当然ray也可以直接保存模型,让你后续直接加载并使用,只需要在report的时候带上checkpoint:
from ray.train import Checkpoint
#...其他代码
torch.save(
model.state_dict(),
os.path.join(temp_checkpoint_dir, "model.pth")
)
checkpoint = Checkpoint.from_directory(temp_checkpoint_dir)
session.report({"loss": val_loss.item()}, checkpoint=checkpoint)调用新的训练函数
在此处我使用了ASHA调度算法。其可以提前终止效果不好的试验并调整超参数。其中metric是你在训练函数中report的值,mode则表明其是越小越好还是越大越好。当然你也可以不使用调度算法,此时就是随机采样了。
from ray.tune.schedulers import ASHAScheduler
scheduler = ASHAScheduler(
metric="loss", mode="min", max_t=5000, grace_period=1500, reduction_factor=4
)
- max_t (最大训练时间): 每次试验中允许运行的最大训练步数/轮数
- grace_period (宽限期): 每个试验必须运行的最小步数,只有在运行超过宽限期后,才会考虑提前终止表现不佳的试验
- reduction_factor (缩减因子): 设置为2表示每个reduction_factor倍数的步数检查一次性能,较小的值会更激进地淘汰试验,较大的值会更保守。注意其最小取值就是2.
随后调用前面定义的train_tune函数,注意你必须在ray.init中指定GPU数量,否则ray不会调用GPU(你也不想在CPU上跑实验吧)。同时在tune.run中每一个实验是可以定义使用分数GPU的。默认情况下ray会吃掉所有可用的资源来并发实验:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
num_cpus = os.cpu_count()
ray.init(num_cpus=num_cpus, num_gpus=1)
analysis = tune.run(
tune.with_parameters(
train_tune, xxx=xxx, device=device
),
config=config,
num_samples=num_samples, # 尝试num_samples次实验
scheduler=scheduler,
resources_per_trial={
"cpu": 4,
"gpu": 0.45,
}, # 每个trial使用4个CPU核心和0.45个GPU
max_concurrent_trials=0, # 无限制并发试验
)当然如果你不希望使用调度算法,想直接使用随机采样(碰运气法),直接调用tune.run即可。不过注意此时你需要在tune.run中设置metric和mode来告知ray如何衡量超参数好坏。
查看调参结果
在训练完成后就可以查看调参结果了。此处我直接获得最优超参数结果:
# 你也可以使用results = tuner.fit()来获得实验中的所有数据
# 其会返回一个ResultGrid对象
# https://docs.ray.io/en/latest/tune/api/doc/ray.tune.ResultGrid.html#ray.tune.ResultGrid
best_config = analysis.get_best_config(metric="loss", mode="min")
print("找到局部最佳超参数:", best_config) # 此处best_config是一个字典类型
ray.shutdown()如果你在上方还传入了checkpoint参数,也可以直接在这一步加载最佳模型:
best_config = analysis.get_best_config(metric="loss", mode="min")
with best_config.checkpoint.as_directory() as checkpoint_dir:
state_dict = torch.load(os.path.join(checkpoint_dir, "model.pth"))
model = Model()
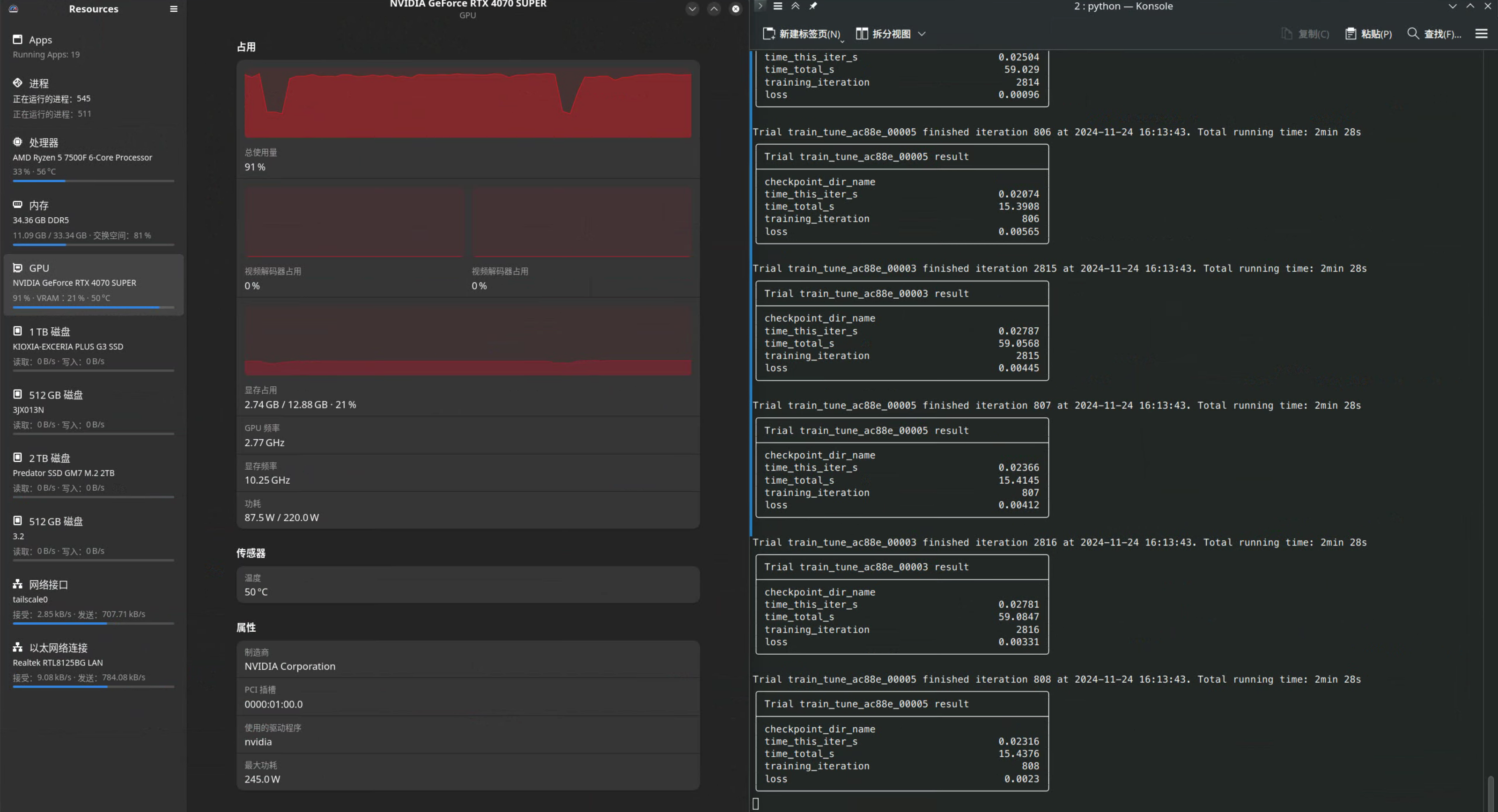
model.load_state_dict(state_dict)随后直接python File.py就开始愉快的自动调参了:
在尝试完成所有的调参次数后(你给定的num_samples),其会自动结束并打印所有调参的结果: