Auto-tuning hyperparameters with ray.tune
For models, the quality of hyperparameter settings can significantly impact performance. However, manually adjusting them can be quite tedious. We can utilize various tools for the automatic tuning of model hyperparameters; for instance, in this article, we use ray.tune for adjustment. It only requires minor modifications—about a dozen lines—to the original code to start the automated tuning process (I personally find it easier to use than NNI).
Introduction
In fact, if you search online, most tutorials utilize NNI (Neural Network Intelligence). However, NNI has not been under development for a long time now, and its repository was archived in a read-only state in September this year.
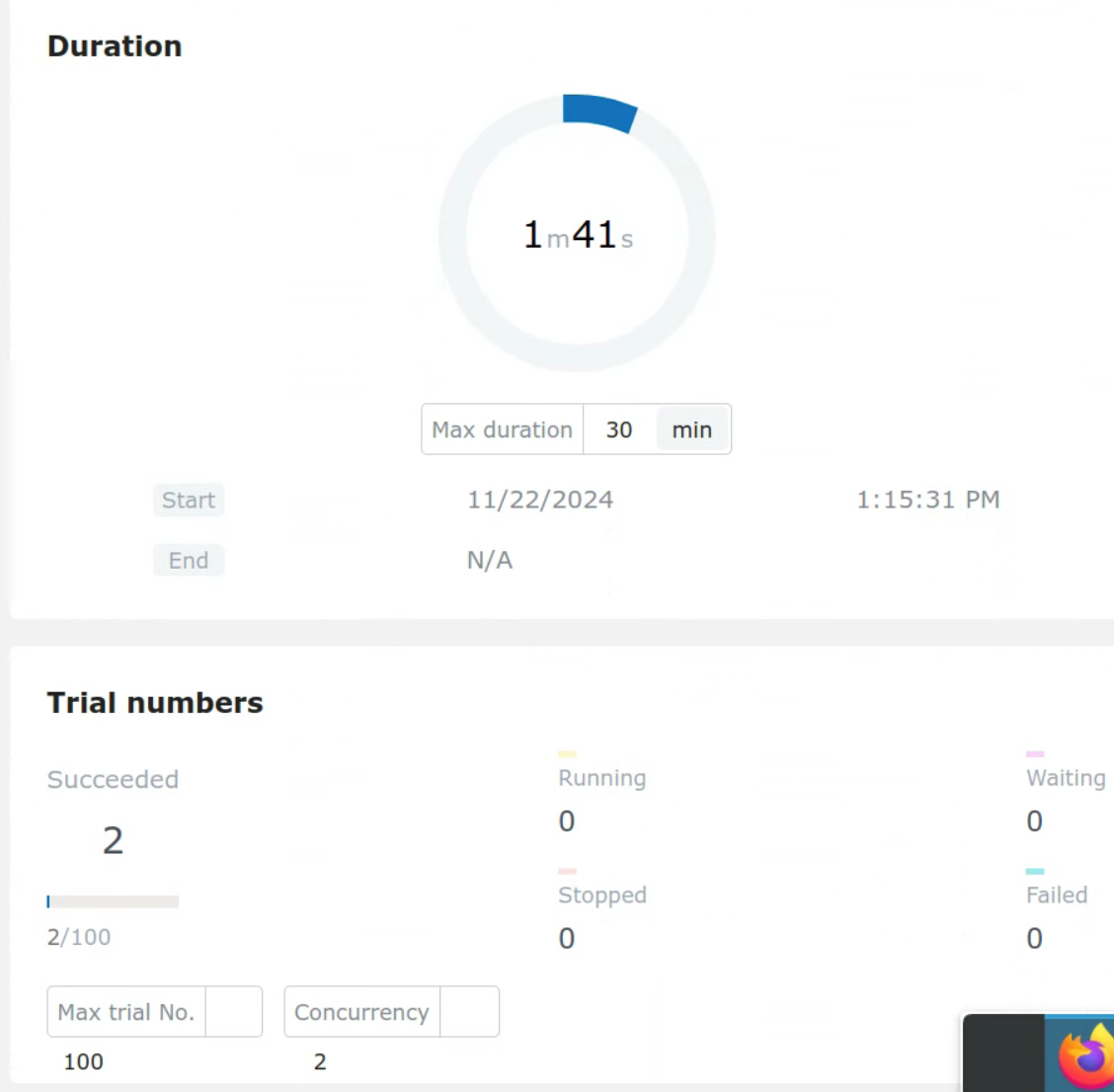
Unfortunately, I encountered a serious bug while using NNI that prevented me from tuning hyperparameters (otherwise, this article wouldn't exist). As illustrated in the image below, I set it to run 100 times to find the optimal hyperparameters, but regardless of my settings, it halts after completing just 2 rounds.
Using ray.tune
⚠️ Note: The following content is based on:
torch = 2.5.1ray = 2.39.0
This will work as long as you are not using an excessively outdated version.
Installation
Ray is essentially a unified framework for distributed deployment and training applications. However, here we only need to use it for hyperparameter tuning, requiring the installation of the relevant tuning components:
pip install "ray[tune]"Modifying the Existing Program
To modify the existing program, you only need to make changes in four areas:
- Define the search space
- Modify the training function to report the current training parameters to ray
- Call the new training function
- Check the tuning results
Defining the Search Space
import ray
from ray import tune
from ray import train as session
# Import all necessary components
#... Other code
config = {
"aaa": tune.choice([128, 256, 512]),
"bbb": tune.choice([512, 1024, 2048]),
"ccc": tune.choice([2, 4, 6, 8]),
"dropout_set": tune.uniform(0.1, 0.4),
}The search space allows ray to adjust the specified hyperparameters within the given range. For example, the hyperparameters aaa, bbb, and ccc are of the choice type, selecting one from the list provided, while dropout_set is a range, selecting a number between 0.1 and 0.4. You can refer to the official ray manual for more definitions of search spaces or even define your own lambda functions to generate the ranges.
Modifying the Training Function
Clearly, during the training process, ray needs a metric to evaluate the performance of the current model based on the hyperparameters. This could be an accuracy or a loss value. In this example, I'm using loss (the lower, the better), so in the subsequent settings, the mode is set to min. If you opt for accuracy, be sure to adjust it to max.
#... Other code
def train_tune(config, xxx, device): # where xxx represents other required parameters
#... Network definition
model = Model(
aaa=config["aaa"],
bbb=config["bbb"],
ccc=config["ccc"],
dropout_set=config["dropout_set"],
).to(device)
#... Other code
for epoch in range(num_epochs):
#... Other code
# Report validation loss for each epoch
session.report({"loss": val_loss.item()})
#... Other codeOf course, ray can also save the model directly, allowing you to load and use it later. Just include the checkpoint parameter when reporting:
from ray.train import Checkpoint
#... Other code
torch.save(
model.state_dict(),
os.path.join(temp_checkpoint_dir, "model.pth")
)
checkpoint = Checkpoint.from_directory(temp_checkpoint_dir)
session.report({"loss": val_loss.item()}, checkpoint=checkpoint)Calling the New Training Function
Here, I employed the ASHA scheduling algorithm, which can terminate ineffective trials early and adjust hyperparameters. The metric parameter corresponds to the value reported in the training function, while mode indicates whether lower or higher values are better. You also have the option to skip the scheduling algorithm, in which case it will simply perform random sampling.
from ray.tune.schedulers import ASHAScheduler
scheduler = ASHAScheduler(
metric="loss", mode="min", max_t=5000, grace_period=1500, reduction_factor=4
)
- max_t (Maximum Training Time): The maximum number of training steps/epochs allowed for each trial.
- grace_period (Grace Period): The minimum number of steps each trial must run; only after surpassing this period will poorly performing trials be considered for early termination.
- reduction_factor: Setting this to 2 means that performance will be checked every
reduction_factormultiples of steps, with smaller values being more aggressive in eliminating trials and larger values being more conservative. Note that the minimum value is 2.
Next, call the previously defined train_tune function. Be sure to specify the number of GPUs in ray.init, otherwise ray won't utilize the GPU (or u want to run it on the CPU...?). Each trial in tune.run can define its GPU usage as well. By default, ray will consume all available resources to run experiments concurrently:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
num_cpus = os.cpu_count()
ray.init(num_cpus=num_cpus, num_gpus=1)
analysis = tune.run(
tune.with_parameters(
train_tune, xxx=xxx, device=device
),
config=config,
num_samples=num_samples, # Attempt num_samples trials
scheduler=scheduler,
resources_per_trial={
"cpu": 4,
"gpu": 0.45,
}, # Each trial uses 4 CPU cores and 0.45 GPU
max_concurrent_trials=0, # Unlimited concurrent trials
)If you prefer not to use a scheduling algorithm and want to employ random sampling (doing it by chance), just call tune.run. Keep in mind that in this case, you will also need to set metric and mode in tune.run to inform ray how to evaluate the quality of the hyperparameters.
Checking the Tuning Results
Once the training is complete, you can check the tuning results. Here, I directly retrieve the optimal hyperparameter settings:
# You can also use results = tuner.fit() to obtain all data from the experiments
# It will return a ResultGrid object
# https://docs.ray.io/en/latest/tune/api/doc/ray.tune.ResultGrid.html#ray.tune.ResultGrid
best_config = analysis.get_best_config(metric="loss", mode="min")
print("Found the best hyperparameters:", best_config) # best_config is a dictionary
ray.shutdown()If you passed the checkpoint parameter earlier, you could also load the best model at this step directly:
best_config = analysis.get_best_config(metric="loss", mode="min")
with best_config.checkpoint.as_directory() as checkpoint_dir:
state_dict = torch.load(os.path.join(checkpoint_dir, "model.pth"))
model = Model()
model.load_state_dict(state_dict)You can then simply run python File.py to start the enjoyable process of automatic hyperparameter tuning:
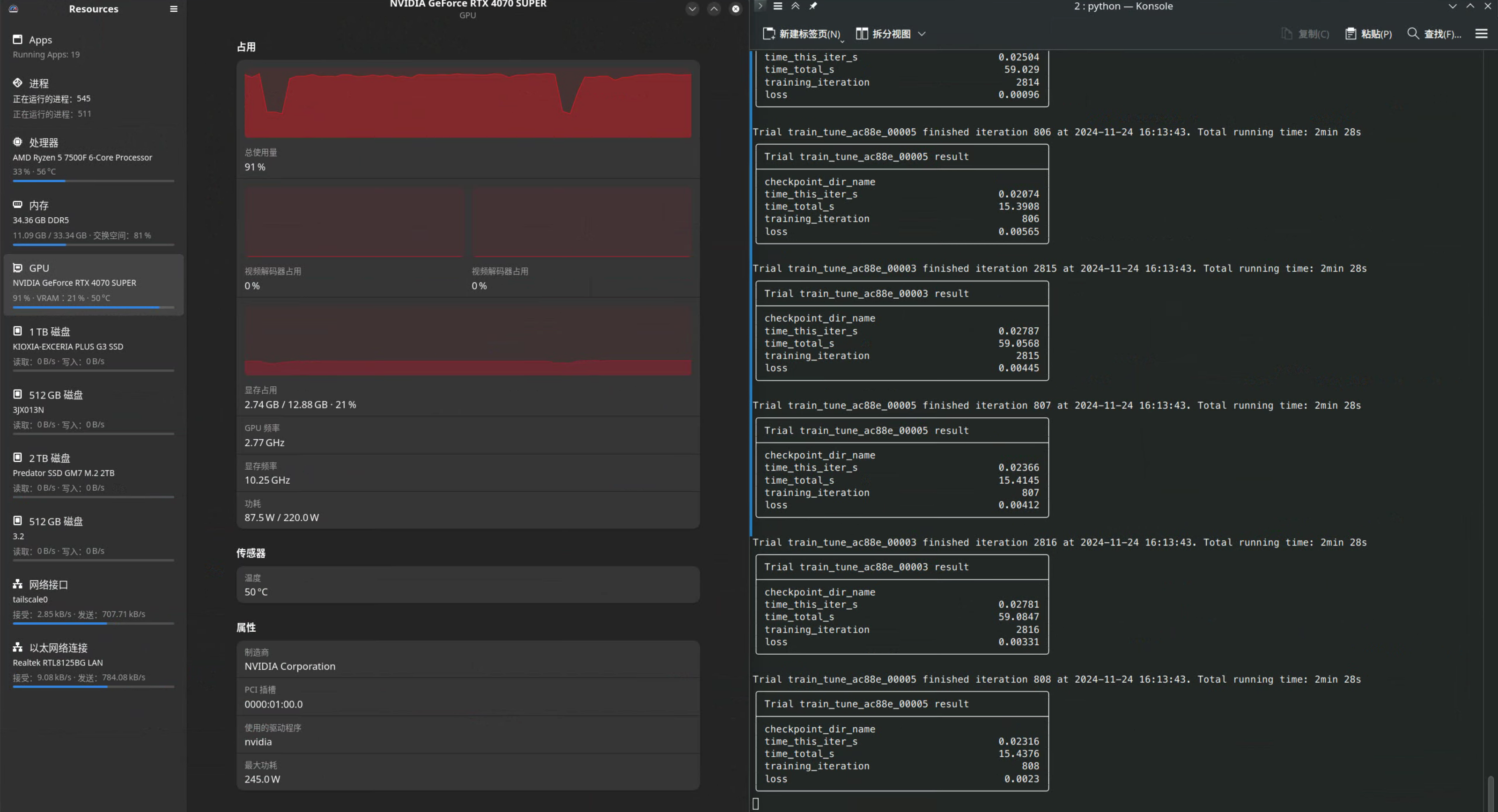
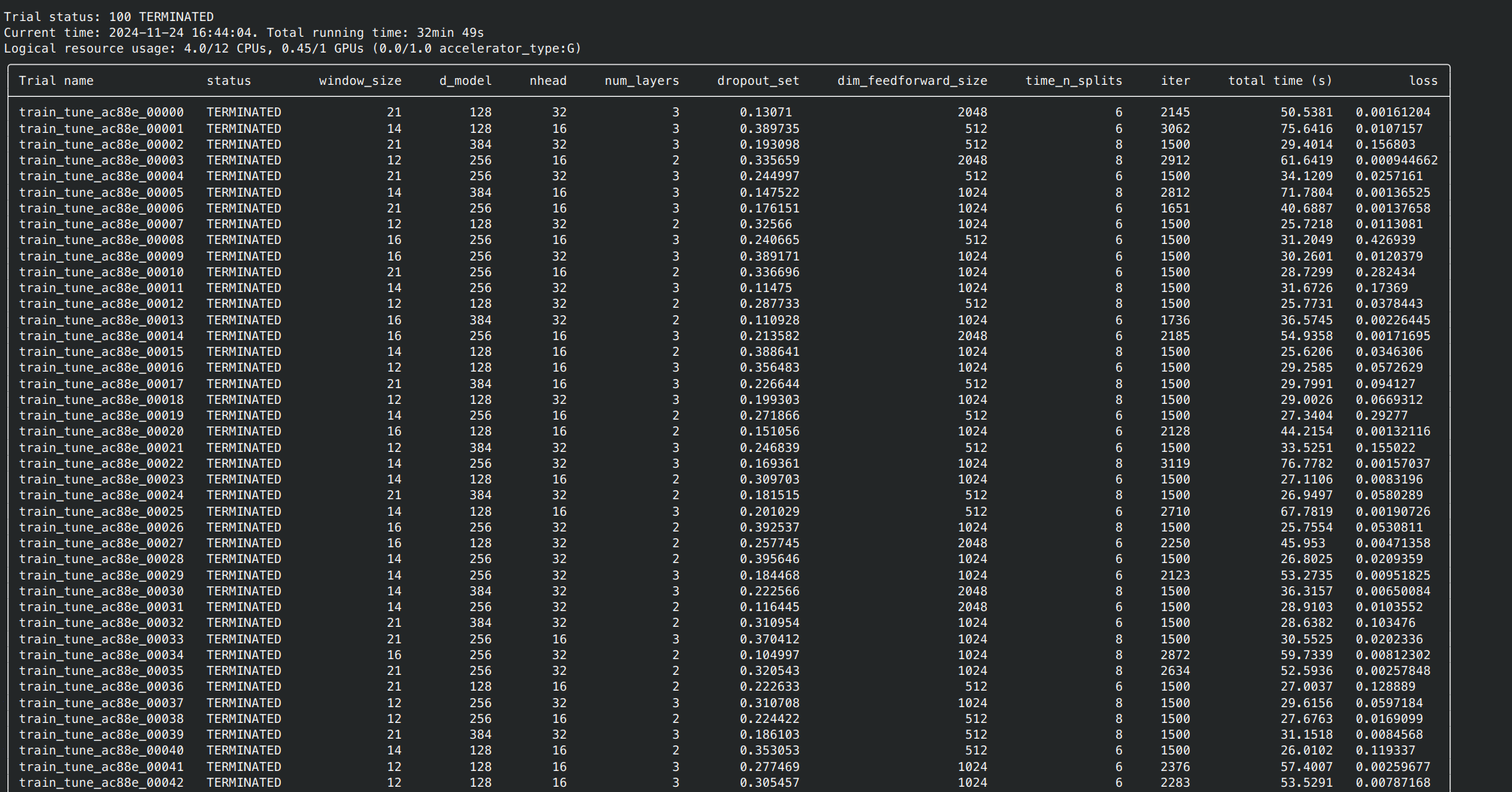
Upon completing all attempts for hyperparameter tuning (as specified by num_samples), it will automatically end and print all the results