Means of attack on AI systems (brief overview)
Recently, I've been researching attacks on AI systems for my final year project. Below is a brief overview of some of the research, mainly on newer adversarial attacks on computer vision and NLP.
PDF File
Click here to view/dowload the PDF file
Slide
Move the focus to the slide and press F to show it in full screen.
Text version
Adversarial attacks on AI system
Main areas of adversarial attacks
- Computer Vision
- Natural Language Processing
- Malware detection (not studied at the moment)
Computer Vision
Digital adversarial attack
- For example, in the medical field, the use of pass-by-image attacks (Using FGSM) can effectively interfere with existing disease prediction algorithms (most of algorithms are based on ResNet-50)
Attacks in the OCR domain
Watermarking attacks, for example, mimic the ink penetration of a scanner, thereby interfering with the recognition of OCR

Pasted image 20241105220005.webp|343
Physical adversarial attack
For example, using real stickers against a model attack

Pasted image 20241105213328.png|353 Optical attacks (e.g. light exposure), a prominent non-invasive method. For example, the image below shows the addition of a translucent sticker in front of the camera.

Some possible attacks way
- Fusion of low and high frequency information from two graphs
- A variant algorithm of the traditional FGSM: adjusting the step size of each dimension to improve the efficiency of the attack(Sun & Yu, 2024)
- Combining with graphical steganography: using GAN to generate images as a backdoor to models(Dong et al., 2023)
NLP
Attacks against tokenizer/NLP
- Use a one-time gradient of all words to compute word salience(Adaptive Gradient-based Word Saliency), a relatively efficient method for creating adversarial text attacks, uses a one-time gradient of all words to compute word saliency(Qi et al., 2024)
- HOMOCHAR:A black-box text confrontation framework, again at the character level(Bajaj & Vishwakarma, n.d.)
Attacks on MLLM
*Multimodal Large Language Model
- Attacks against positioning tasks, against MLLM can be made from graphics or input text(Gao et al., 2024)
Attacks on MLLM
Attack by generating adversarial images (relatively more likely to generate harmful information with separate inputs, which are initialized with random noise) against image prefixes that are optimized to maximize the generation of harmful content, followed by a problem that then embeds harmful semantics(Wang et al., 2024)
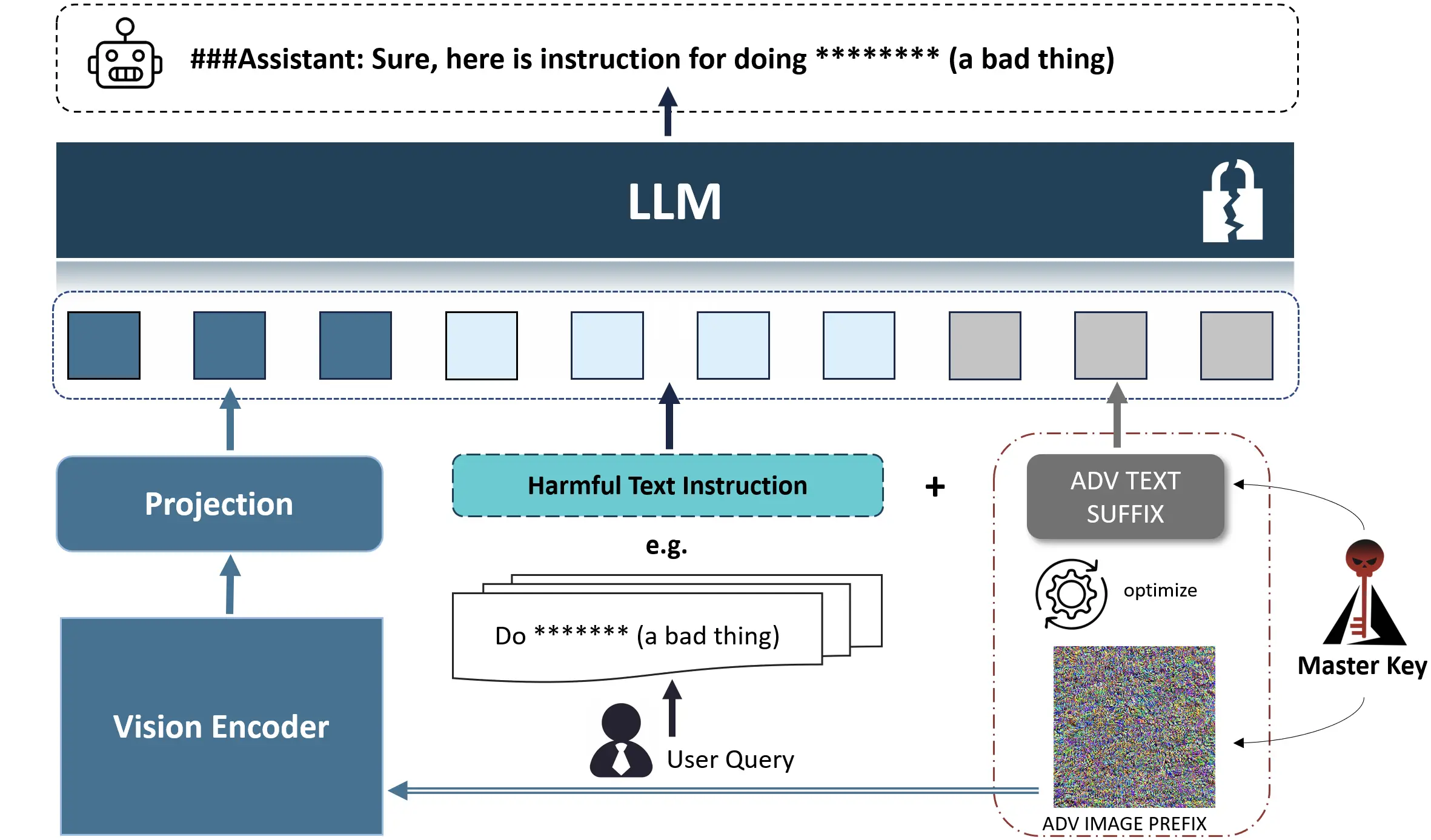
Pasted image 20241105233900.webp|431
Common Attack Tools
model attack
- Adversarial Robustness Toolbox
- Foolbox
- CleverHans
Steganography
- OpenStego(steganography)
- text_blind_watermark(Text Blind Watermark)
- echo_watermark(audio watermark)